
Ever spent hours labeling images, ranking chatbot replies, or tagging text, wondering, "What's this all for?" As an AI data trainer or annotator, you're the backbone of artificial intelligence, shaping models like Grok, self-driving cars, and medical diagnostics. Your clicks and judgments don't just vanish—they fuel a complex process that makes AI smarter, safer, and more human-like.
This guide unveils the magic behind your work, diving into Supervised Fine-Tuning (SFT), Reinforcement Learning with Human Feedback (RLHF), and evaluation loops. Packed with real-world stories, data, vivid visuals, and practical tips, it's your roadmap to understanding—and maximizing—your impact. Ready to see how you're shaping the future of AI? Let's dive in!
- 1.5 million annotators globally powering AI models (McKinsey, 2025)
- 95%+ accuracy achieved through human validation
- 20-30% performance boost from high-quality annotations
- 3 key processes that transform your work into AI intelligence
Your Labels: The Fuel for AI's Brain
When you label an image or rank a response, you're not just completing a task—you're teaching AI to think. In 2025, over 1.5 million annotators globally (McKinsey) create the datasets that power AI models. But what happens after you hit "submit"? Here's the journey:
- Validation & Quality Assurance: Human reviewers or automated checks ensure your labels meet 95%+ accuracy. Errors get flagged for correction.
- Dataset Integration: Your work joins thousands of annotations in a massive dataset, like a puzzle piece in a giant mosaic.
- Model Training: Algorithms learn patterns from your labels, enabling tasks like recognizing cats or answering questions.
- Testing & Evaluation: The model is tested on new data to gauge performance, often requiring more annotations.
- Iteration: Feedback loops refine the model, restarting the cycle for better accuracy.
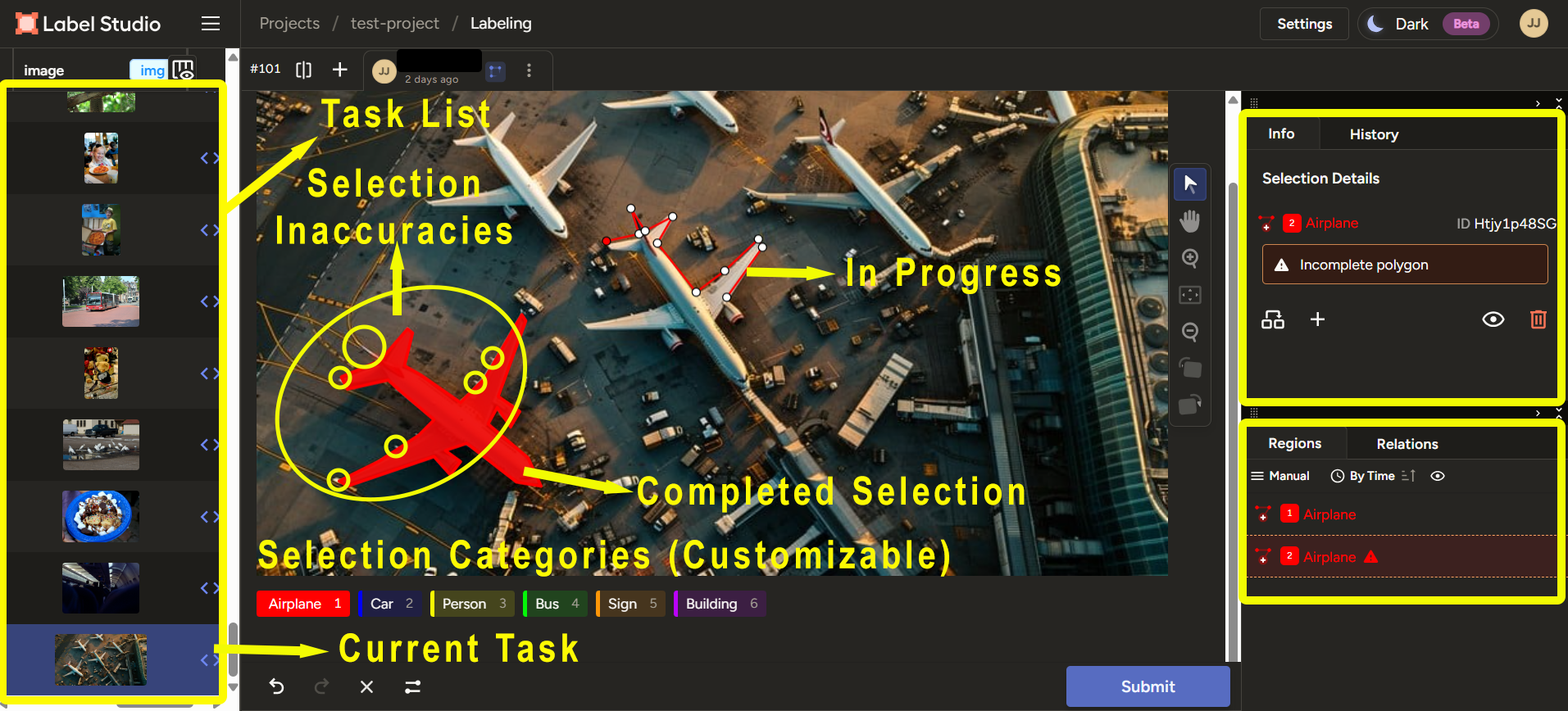
Label Studio's annotation interface in action: task progress tracking, annotation tools, main labeling area, label categories, and submission controls - everything an annotator needs in one screen.
Real-World Impact: @DataTaggerX's Story
X/TwitterA 2025 X post by @DataTaggerX described labeling 500 images for a retail AI. Their work helped the model identify products with 98% accuracy, launching in stores worldwide. "My tags are on shelves now!" they shared.
"My tags are on shelves now! Never thought my annotations would power AI that helps millions of shoppers find products."
Data Point
A 2024 TED study found high-quality human annotations boost model accuracy by 20-30% in tasks like object detection.
Supervised Fine-Tuning (SFT): Precision Through Your Labels
SFT is where your annotations give AI laser-like focus. It's like teaching a child by showing clear examples. Here's how it works:
- Curated Examples: You label data, like tagging "happy" on a smiling emoji or drawing boxes around pedestrians.
- Training Phase: The model adjusts its parameters to mimic your labels, learning to predict correctly.
- Outcome: Higher precision, reducing errors in tasks like sentiment analysis or image recognition.
Success Story: Priya's SFT Breakthrough
RemotasksPriya, a Remotasks annotator (anonymized, 2024 Reddit), labeled 1,000 text snippets for a chatbot's sentiment analysis. Her SFT work cut the model's misclassification rate from 15% to 5%. "I taught it to read emotions," she said.
"I taught it to read emotions. My labels went from basic sentiment to nuanced understanding of context and tone."
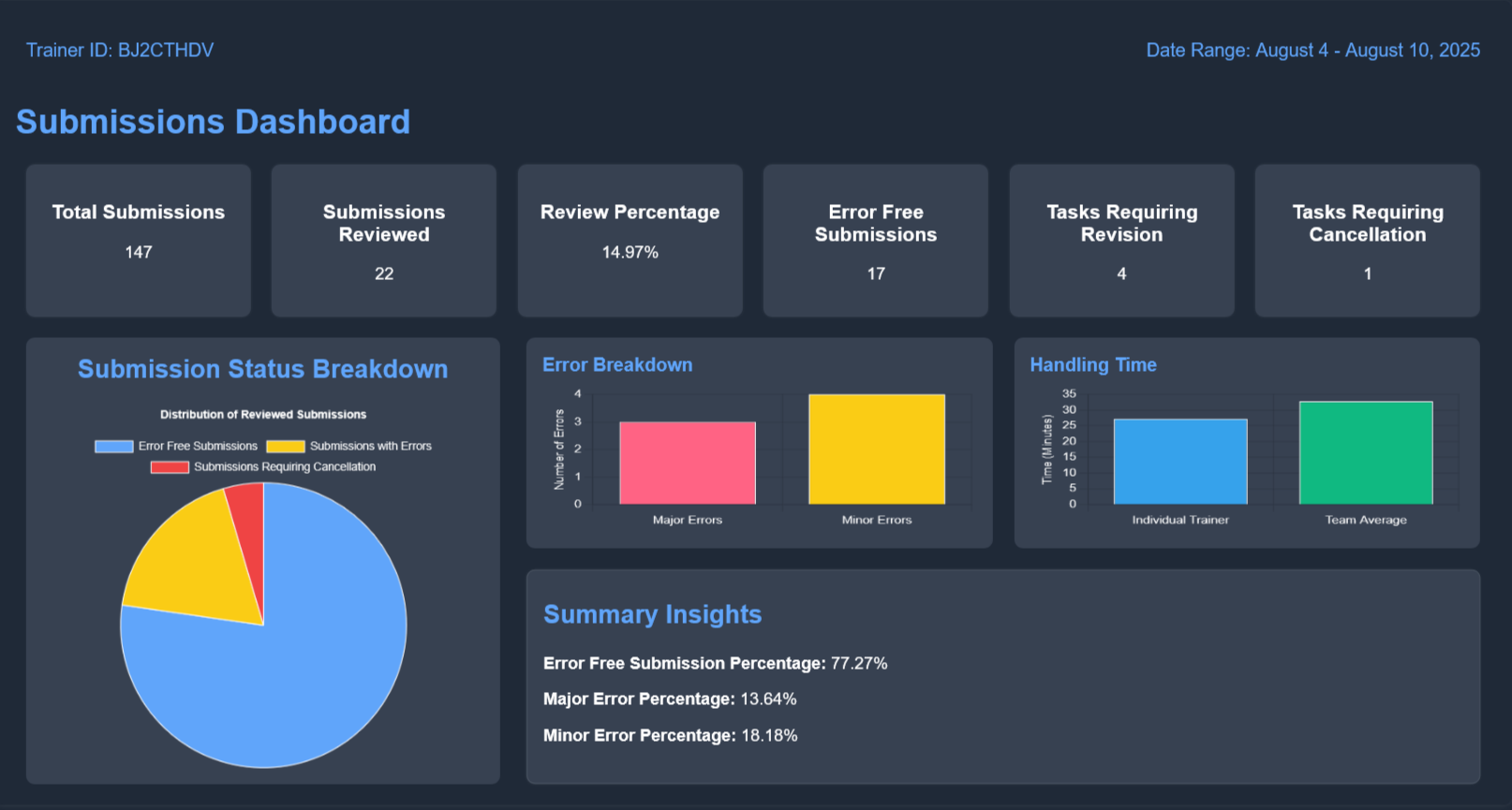
Sample annotation dashboard displaying review rates, error breakdown, and handling times — key metrics used by annotators and reviewers to track quality and efficiency.
Data Point
A 2025 Scale AI report noted SFT with human labels improves model performance by 25% in NLP tasks.
Reinforcement Learning with Human Feedback (RLHF): Shaping AI's Soul
RLHF takes AI training to the next level, using your rankings to align models with human values. It's like coaching AI to be helpful and ethical. Here's the process:
- Generation & Comparison: The model produces multiple outputs (e.g., chatbot replies).
- Human Ranking: You score or rank them based on quality, safety, or tone.
- Reward Signals: Your rankings create "rewards" the model optimizes for.
- Continuous Improvement: The model refines its behavior, becoming more human-like.
Safety Champion: Jamal's RLHF Impact
Scale AIJamal, a Scale AI evaluator (2025 X post), ranked 200 chatbot responses for a safety project. His feedback taught the model to avoid harmful replies, achieving 93% safe outputs. "I'm keeping AI trustworthy," he shared.
"I'm keeping AI trustworthy. Every ranking I make helps the model understand what's helpful versus harmful."
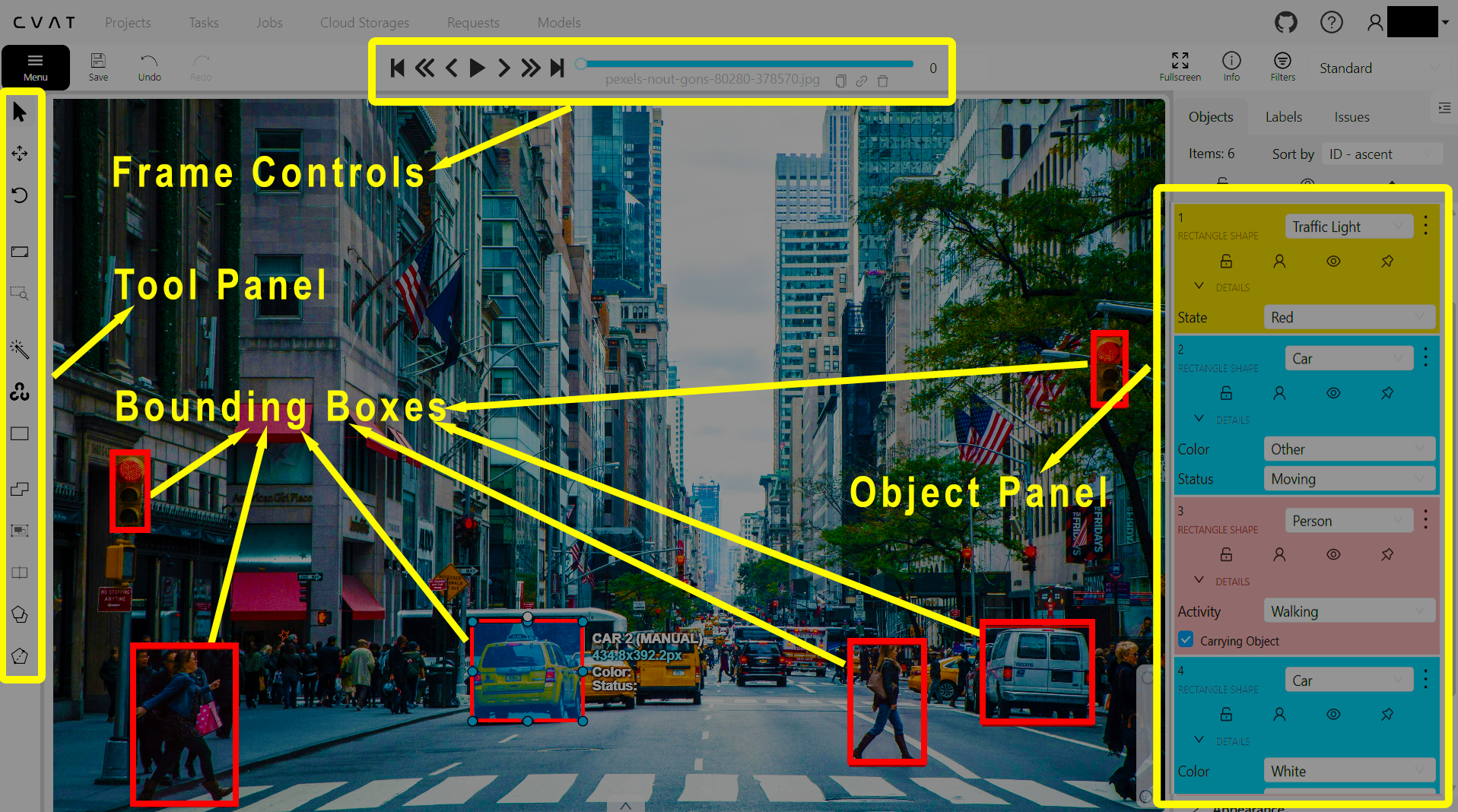
CVAT's interface demonstrates how human feedback guides AI training - every bounding box teaches the model to better recognize objects.
Data Point
A 2025 xAI study found RLHF with human feedback cuts harmful model outputs by 30% in conversational AI.
Evaluation Loops: Your Work as the Final Gatekeeper
Evaluation loops are AI's quality control, ensuring models perform reliably. Your annotations play a starring role:
- Initial Evaluation: Models are tested on benchmark datasets you labeled.
- Error Analysis: Your annotations pinpoint where models fail (e.g., mislabeling sarcasm).
- Feedback Integration: New annotations refine the model.
- Final Validation: Your labels confirm improved performance.
Safety Guardian: Aisha's Evaluation Impact
TELUSAisha, a TELUS annotator (2024 LinkedIn post), evaluated 300 image labels for an autonomous vehicle model. Her error catches improved pedestrian detection by 10%, saving potential lives. "My work keeps roads safer," she said.
"My work keeps roads safer. Every annotation I check could prevent an accident."
Data Point
A 2024 NVIDIA report showed evaluation loops with human annotations reduce model errors by 15-20% in safety-critical tasks.
Why Your Annotations Matter: The Heart of AI Quality
Your work isn't just a task—it's the foundation of AI's capabilities. Here's why:
- Contextual Understanding: Your labels teach models to grasp sarcasm, cultural nuances, or edge cases. E.g., a 2025 Reddit post by u/LabelPro noted their annotations helped a chatbot understand slang, boosting user satisfaction.
- Accuracy & Reliability: Precise labels ensure models deliver dependable results, like diagnosing diseases or filtering spam.
- Ethical Alignment: Your rankings guide AI to avoid bias or harm, as seen in Jamal's safety project.
- Adaptability: Diverse annotations make models versatile, handling varied real-world scenarios.

Human trainer evaluating AI model responses - the direct feedback that improves AI performance.
Pro Tip
Pay extra attention to edge cases and cultural nuances in your annotations. These tricky details are where AI models often fail — and where your human insight adds the most value.
Real-World Impact: Your Work Changes Lives
Your annotations ripple across industries:
- Healthcare: Accurate labels help AI diagnose cancer with 95% precision (2025 MIT study).
- Autonomous Driving: Detailed annotations improve object detection, cutting accidents by 20% (2024 NVIDIA data).
- Content Moderation: Your rankings filter 90% of harmful content, per 2025 Meta report.
Voice for Millions: Sam's Audio Impact
ClickworkerSam, a Clickworker annotator (2024 X post), labeled audio for a voice assistant. His work enabled it to understand diverse accents, helping millions communicate. "I gave AI a voice," he said.
"I gave AI a voice. My audio annotations helped the model understand accents from around the world."
Maximize Your Impact: 5 Tips to Shine
Want to make your annotations count even more? Here's how top annotators excel:
- Nail Accuracy: Double-check labels to hit 95%+ accuracy. A 2025 X post by @AIHustlerX said this earned them a $200 bonus.
- Master Guidelines: Read instructions twice to avoid errors, saving time and boosting quality.
- Learn AI Basics: Understand SFT or RLHF via Coursera's "AI for Everyone" (free audit, 10 hours) to provide sharper feedback.
- Stay Consistent: Use tools like Notion to track your labeling style, ensuring uniformity.
- Engage with Peers: Join X or Reddit's r/datascience to swap tips. A 2024 X thread helped 50 annotators improve RLHF rankings.

The continuous feedback loop between human trainers and AI systems, showing how evaluations drive measurable improvements in model performance, safety, and usefulness.
Conclusion: You're Shaping AI's Future
Your annotations, rankings, and evaluations aren't just tasks—they're the heartbeat of AI, making models accurate, ethical, and impactful. By understanding SFT, RLHF, and evaluation loops, you can amplify your role and take pride in changing the world.
Start today: review your next task's guidelines, track your accuracy, and join our X community to share your impact. You're not just an annotator—you're an AI trailblazer!
How has your work shaped AI?
Share your story below and connect with fellow AI trainers!